
In this project, a regional law firm brought me in to add an AI layer on top of their existing document management system. The goal was to give the legal team the ability to use a chat bot to query and analyze across separate case files. In a nutshell, they were looking for an AI paralegal. However, a hard constraint made this a little more challenging – it had to be zero-retention*. No raw files could be sent in their entirety directly to the AI services, and no document data could persist between runs for privacy and legal reasons. The system had to be fast enough to be useful while storing nothing between runs.
The solution I developed was a middleware layer connecting a ChatGPT Custom GPT frontend to iManage, the firm’s document management platform. The middleware handles every request, verifies authentication, retrieves and processes relevant documents entirely in memory, and passes cleaned text chunks back to the chatbot interface. No raw files transmitted back. No persistent state. No data retained between sessions. No direct AI access to the document storage.
* LLMs will not steal my beloved em dash from me. I know this is now a calling card of AI-written text, but I promise I’m a real person writing this with my own keyboard. I also know that’s exactly what an LLM would say too. I can’t win…
Demo

Middleware System Design
The middleware is a serverless REST API deployed on Azure Functions that sits between a ChatGPT Custom GPT frontend and iManage, the law firm’s enterprise document management platform. Attorneys can submit a plain-English request in chat such as, “Summarize the grounds asserted for all Rule 12(b)(6) motions we’ve filed in the Ninth Circuit in the last 3 years.” After analyzing the message, ChatGPT uses a custom-built GPT to construct a query and call the middleware API to get the data it needs for analysis. The middleware then retrieves, cleans, and processes relevant files from iManage before passing the needed text chunks back to the LLM. The chatbot then analyzes those text chunks and synthesizes a response based on the customized system instructions and original user request.
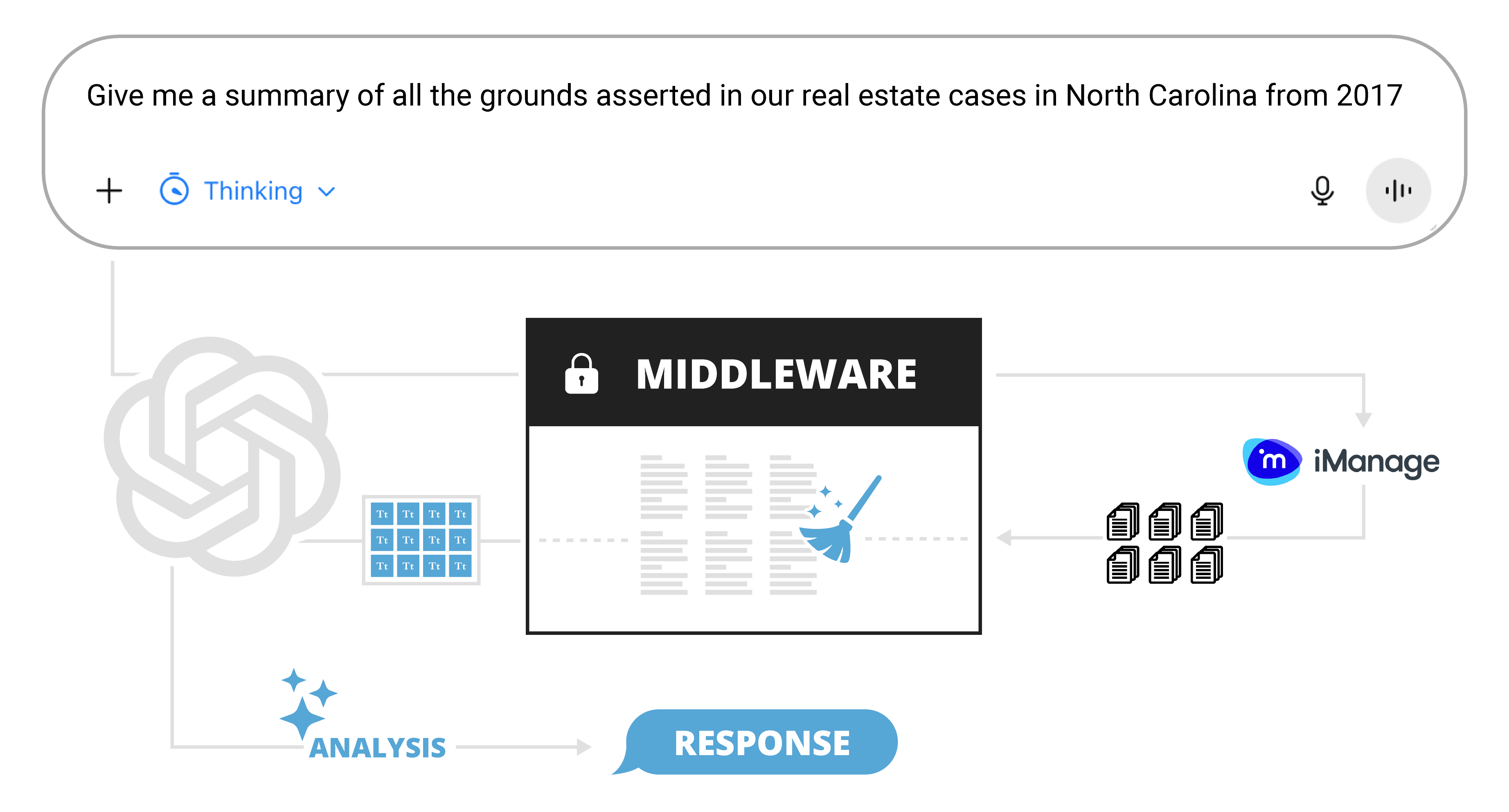 The custom GPT required fine tuning of the schema to make sure it constructed queries correctly. After some tuning of the schema and system instructions, the custom GPT was ultimately able to properly handle typical requests alongside complex legal phrasing, ambiguous terminology, tricky dates, and complicated structured search queries. It was also designed to work with the user to clarify a request before firing off an API call. I also built custom error-handling into the middleware response layer, since ChatGPT doesn’t surface non-200 HTTP responses gracefully to the user (at least not at this time).
The custom GPT required fine tuning of the schema to make sure it constructed queries correctly. After some tuning of the schema and system instructions, the custom GPT was ultimately able to properly handle typical requests alongside complex legal phrasing, ambiguous terminology, tricky dates, and complicated structured search queries. It was also designed to work with the user to clarify a request before firing off an API call. I also built custom error-handling into the middleware response layer, since ChatGPT doesn’t surface non-200 HTTP responses gracefully to the user (at least not at this time).
Some constraints from the client and the Azure Functions system made this an interesting challenge. First, certain file processing libraries that would have made cleaning easier weren’t available within the Azure Functions memory limits. So, the pipeline had to achieve the same quality of output through leaner approaches. Second, zero-retention meant that nothing could be cached between runs. Without persistent storage, every cleaning decision had to be fast enough to avoid ChatGPT’s response timeout.
Security was also a huge focus of the design. With access to sensitive legal files, the system had to take multiple precautions to ensure protected data couldn’t be inadvertently accessed. The system uses a multi-leg authentication flow out of necessity to ensure the LLM never gets direct access to the file system, and this design also provides redundant security layers. It additionally implements an OBO (on-behalf-of) setup so the user querying the system can only access files in the document repo they’re authorized to view. The system also utilizes a SAML authentication in one of the authentication hops. This provides a distinct security advantage over a standalone key that would have granted any low-level authorized user access to the entire document storage – not good!
File Cleaning Pipeline
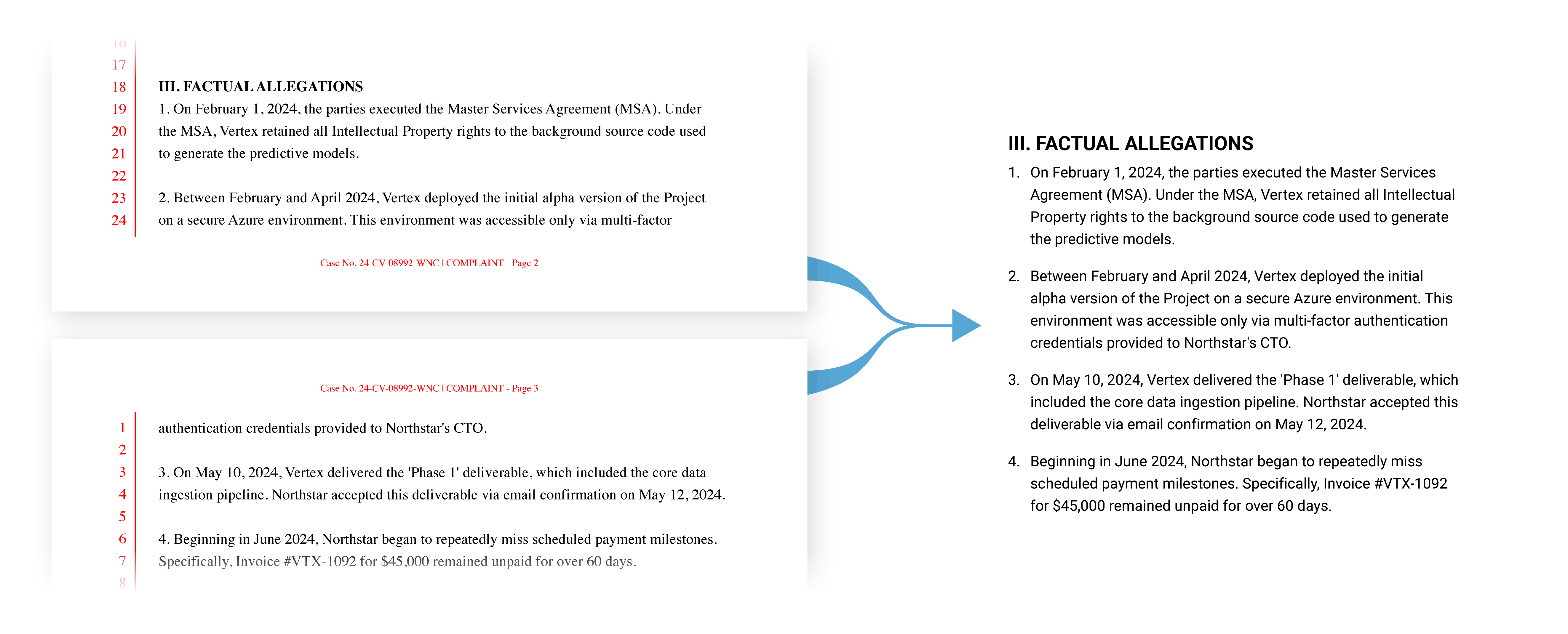
Raw files are first downloaded from iManage as bytes and passed through a custom extractor before cleaning begins. The resulting raw text is not usable to start. A legal document pulled straight from iManage frequently has issues like text splits at every visual line break, running headers and footers embedded mid-paragraph, page numbers, tables extracted as disordered character fragments, legal pleading line numbers, and sentences split at page boundaries. Feeding that directly to a language model produces poor results. Garbage in, garbage out.
The cleaning step analyzes the document to reconstruct various formatting such as lists, tables, and text header hierarchies. All the cleaning and format analysis allows the pipeline to output a standardized format for the chunker, and ultimately the chatbot.
Middleware Advantages
The design of the system creates a few key advantages worth highlighting.
- It enforces data security. The LLM can’t inadvertently access or modify files it shouldn’t. It keeps the LLM out of the sensitive document repository while still providing it access to necessary portions of the files for analysis.
- Key components are modular. Therefore, the system can be easily integrated with other document storage systems such as Sharepoint in the future. Document cleaning can be applied regardless of where the source files originate.
- Easier to debug. By keeping the system’s components narrowly focused, it makes it much easier to debug compared to giving the LLM direct access to the files. If something goes wrong, it’s easy to isolate whether the issue is in the source material or the analysis by inspecting the returned text. Without this middleware, the entire system would be much more of a black box and extremely difficult to troubleshoot.
- The system is easily transferrable. It’s not limited to any one LLM. Porting to Gemini or Claude would be straightforward and would only require swapping the system instructions and schema. The middleware logic carries over unchanged.